
语音生成与感知模型
发音与感知模型
声门
声带之间的间隙称为声门。
主要功能:产生激励。
声道
声道指声门至嘴唇的所有发音器官,包括咽喉、口腔和鼻腔。
主要功能:传输并调制声波。
声道的形状变化由舌、软腭、唇、牙决定。
语音生成动作
语音生成可分为两种功能:
- 激励:由声门产生的基本声波。
- 调制:通过声道形状的变化改变声波的频率特性。
语音生成框图
声门 (激励) ➔ 声道 (调制) ➔ 嘴唇 (辐射语音)
基音频率
由声带张开闭合的周期决定。
- 男性:50-250Hz
- 女性:100-500Hz
浊音与清音
- 浊音:由声带振动产生,包括所有元音和部分辅音。
- 清音:不通过声带振动产生,包括另一部分辅音。
语音生成过程
- 空气从肺部排出形成气流。
- 冲击声带:
- 声带紧绷:形成准周期性脉冲空气流,产生浊音。
- 声带舒展:形成摩擦音或爆破音。
- 空气流经过声道调制后从口或鼻腔辐射,形成语音。
共振峰
声道是谐振腔,有许多谐振频率,称为共振峰。 共振峰是声道的重要声学特征。
听觉掩蔽效应
- 人耳听觉频率范围:20Hz-20kHz。
- 语音感知强度范围:0-130dB声压级。
- 掩蔽效应:一个声音的听觉感受性受到同时存在的另一个声音的影响。
语音信号数字模型的组成
- 语音信号数字模型:激励模型,声道模型,辐射模型
- 声道模型:声管模型,共振峰模型
- 共振峰模型:分为级联型,并联型和混合型
数字语音处理
语音信号基本特性
- 语音信号频率范围:300-3400Hz。
- 常用采样率:8kHz。
语音预处理
预处理
包括:预加重,端点检测,加窗分帧
预加重
目的:增强高频分辨率,减少口唇辐射影响。
短时处理
- 加窗:窗长一般选取100-200ms。
- 窗宽较大:平滑作用明显,反映能量变化较小。
- 窗宽较小:反映细节快变,包络变化不明显。
短时平均能量
用途:
- 区分清音与浊音。
- 区分有声与无声。
- 语音识别的辅助参数。
短时自相关函数
- 浊音:具有明显周期性。
- 清音:无周期性,类似噪声。
倒谱分析
实现:解卷(卷积关系变换为求和关系)
- 将语音信号的声门激励信息与声道响应信息分离。
- 用于提取声道共振特征和基音周期。
- 倒谱:频谱(Spectrum)的前四个字母倒过来。
共振峰
- 语音的主要频率成分,携带声音的辨识属性
- 提取共振峰:共振峰的位置和转变过程
语音端点检测
端点检测法
指从包含语音的一段信息中确定出语音的起始点和结束点。
双门限比较法
- 第一级判决:
- 根据短时能量选较高门限T1,粗判定语音段。
- 根据背景噪声平均能量确定较低门限T2,精确定位语音段。
- 第二级判决:
- 用短时平均过零率,进一步搜索语音段的起止点。
- 门限T3由背景噪声平均过零率确定。
语音特性与噪声
语音特性
- 语音是时变、非平稳的随机信号,同时具有短时平稳性。
- 语音分为清音与浊音。
- 语音信号可用统计分析描述。
噪声特性
- 加性噪声:直接叠加在语音信号上。
- 非加性噪声:需通过变换处理成加性噪声。
噪声分类
- 周期性噪声:如机械噪声,用功率谱与滤波去除。
- 冲激噪声(脉冲噪声):通过幅度阈值检测并消除。
- 宽带噪声:难以去除,用白化处理或其他方法。
- 语音干扰噪声:如“鸡尾酒会效应”,通过语音增强算法处理。
语音增强算法分类
- 根据是否建立模型:
- 模型算法:
- 参数方法
- 统计方法
- 非模型算法
- 根据麦克风数量:
- 单通道语音增强算法
- 多通道语音增强算法
- 根据处理域:
- 时域
- 频域
- 巴克域
- 子空间域
- 小波域
谱减法优缺点
优点:
- 无需使用端点检测方法区分语音段和无声段。
- 算法简单,易于实现。
缺点:
- 频谱直接相减会导致增强后的语音产生“音乐噪声”。
- 适用的信噪比范围较窄。
- 在低信噪比时对语音可懂度损伤较大。
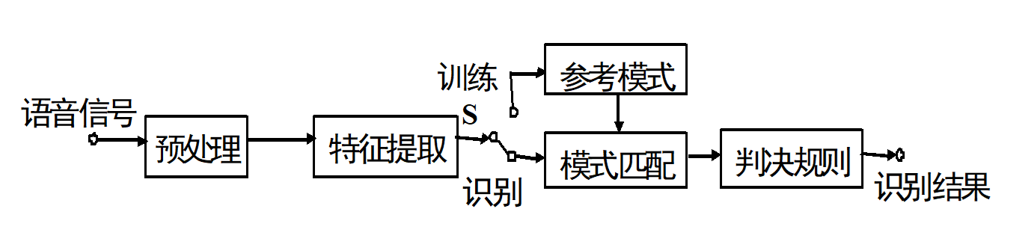
语音识别系统
系统组成
流程图:

- 预处理:包括预加重、端点检测。
- 特征提取:获取语音信号特征参数。
- 训练识别网络:建立模板和模型。
识别方法
- 基于声道模型与语音知识。
- 模式匹配方法:如VQ、DTW。
- 统计模型方法:如HMM。
- 人工神经网络方法:如深度学习。
语音识别过程
训练过程
- 预处理:输入语音经过预处理。
- 特征提取:提取语音信号的特征。
- 模板建立:基于提取的特征建立语音模板。
识别过程
- 特征比较:将输入语音特征与现有语音模板进行比较。
- 最优匹配:找出一系列最优匹配的模板。
- 结果输出:通过查表给出计算机的识别结果。
隐马尔可夫模型 (HMM)
是一个统计模型
双重随机过程:
- 短时平稳段统计特征。
- 段间动态转变特性。
在语音识别的应用
- 语音识别的困难:对语音的发音速率和声学变化建立模型
HMM通过以下方式解决上述问题:
- 状态转移概率:模拟发音速率的变化,反映大脑根据语法和言语需求调整音素参数的过程。
- 观察输出概率:模拟声学变化,通过依赖状态的输出概率来描述可观测的语音时变序列。
步骤:
- 信号预处理。
- 特征提取。
- 训练HMM。
- 测试集识别。
参数
- N:模型的状态数目
- M:观测符号数
- A:状态转移概率分布
- B:状态的观测符号概率分布
- π:初始状态分布
题目
判断题
- 声门的主要功能是传输并调制声波。
- 答案:错误
- 解析: 声门的主要功能是产生激励,而传输并调制声波是声道的功能。
- 基音频率由声带张开闭合的周期决定,男性的基音频率范围通常为50-250Hz。
- 答案:正确
- 解析: 基音频率确实由声带振动周期决定,男性的基音频率范围通常为50-250Hz。
- 清音是通过声带振动产生的。
- 答案:错误
- 解析: 清音不通过声带振动产生,浊音才是通过声带振动产生的。
- 共振峰是声道的重要声学特征,反映了声道的谐振频率。
- 答案:正确
- 解析: 共振峰是声道的谐振频率,是语音的重要声学特征。
- 预加重的目的是增强低频分辨率。
- 答案:错误
- 解析: 预加重的目的是增强高频分辨率,减少口唇辐射的影响。
单选题
- 声道的形状变化主要由哪些器官决定?
- A. 声带
- B. 舌、软腭、唇、牙
- C. 肺部
- D. 鼻腔
- 答案:B
- 解析: 声道的形状变化由舌、软腭、唇、牙决定。
- 以下哪个频率范围是语音信号的常用频率范围?
- A. 20Hz-20kHz
- B. 300-3400Hz
- C. 50-250Hz
- D. 100-500Hz
- 答案:B
- 解析: 语音信号的常用频率范围是300-3400Hz。
- 以下哪种噪声属于周期性噪声?
- A. 冲激噪声
- B. 宽带噪声
- C. 机械噪声
- D. 语音干扰噪声
- 答案:C
- 解析: 周期性噪声如机械噪声,可以通过功率谱与滤波去除。
- 在语音识别系统中,以下哪一步骤不属于预处理阶段?
- A. 预加重
- B. 端点检测
- C. 特征提取
- D. 加窗
- 答案:C
- 解析: 特征提取属于特征提取阶段,而不是预处理阶段。
- 以下哪种方法属于语音识别的统计模型方法?
- A. VQ(矢量量化)
- B. DTW(动态时间规整)
- C. HMM(隐马尔可夫模型)
- D. 深度学习
- 答案:C
解析: HMM(隐马尔可夫模型)是一种统计模型方法。
简述题
- 简述语音生成的过程。
- 答案:
- 空气从肺部排出形成气流。
- 气流冲击声带,声带振动产生基本声波(激励)。
- 声波经过声道(包括咽喉、口腔和鼻腔)的调制,声道的形状变化由舌、软腭、唇、牙等器官决定。
- 调制后的声波从口或鼻腔辐射出去,形成语音。
- 什么是听觉掩蔽效应?
- 答案:
- 听觉掩蔽效应是指一个声音的听觉感受性受到同时存在的另一个声音的影响。具体来说,当一个声音(掩蔽声)存在时,另一个声音(被掩蔽声)的听觉阈值会升高,导致被掩蔽声难以被感知。
- 简述短时处理中加窗的作用。
- 答案:
- 加窗的作用是将语音信号分割成短时段进行处理,以便分析语音的短时特性。窗长一般选取100-200ms,窗宽较大时平滑作用明显,反映能量变化较小;窗宽较小时反映细节快变,包络变化不明显。
- 什么是倒谱分析?它的主要用途是什么?
- 答案:
- 倒谱分析是将语音信号的声门激励信息与声道响应信息分离的一种方法。它的主要用途是提取声道的共振特征和基音周期,从而帮助分析语音的声学特性。
- 简述语音识别系统的基本组成。
- 答案:
- 预处理:包括预加重、端点检测等。
- 特征提取:获取语音信号的特征参数。
- 训练识别网络:建立模板和模型。
- 识别:通过模式匹配、统计模型或人工神经网络等方法进行语音识别。
综合题
- 请详细描述语音生成与感知模型中的声道和声门的作用,并结合语音生成框图解释语音生成的过程。
- 答案:
- 在语音生成与感知模型中,声门和声道是两个关键部分。
- 声门: 声门是声带之间的间隙,主要功能是产生激励。当空气从肺部排出时,气流通过声门,声带振动产生基本声波,这个声波是语音生成的起点。
- 声道: 声道指从声门到嘴唇的所有发音器官,包括咽喉、口腔和鼻腔。声道的主要功能是传输并调制声波。声道的形状变化由舌、软腭、唇、牙等器官决定,这些变化会改变声波的频率特性,从而形成不同的语音。
- 语音生成框图:
- 声门(激励):声带振动产生基本声波。
- 声道(调制):声波经过声道的调制,声道的形状变化改变声波的频率特性。
- 嘴唇(辐射语音):调制后的声波从嘴唇或鼻腔辐射出去,形成最终的语音。
- 请结合语音信号的短时处理,解释短时平均能量和短时自相关函数在语音分析中的作用。
- 答案:
- 短时平均能量: 短时平均能量是语音信号在短时段内的能量平均值。它的主要用途包括:
- 区分清音与浊音:浊音的能量通常较高,而清音的能量较低。
- 区分有声与无声:有声段(如元音)的能量较高,而无声段(如停顿)的能量较低。
- 作为语音识别的辅助参数:短时平均能量可以帮助识别语音的起始和结束点。
- 短时自相关函数: 短时自相关函数用于分析语音信号的周期性。它的主要用途包括:
- 区分浊音与清音:浊音具有明显的周期性,自相关函数会显示出周期性的峰值;而清音无周期性,自相关函数类似噪声。
- 提取基音周期:通过自相关函数的峰值间隔,可以估计浊音的基音周期。
- 短时平均能量: 短时平均能量是语音信号在短时段内的能量平均值。它的主要用途包括:
- 请详细描述语音识别系统中的隐马尔可夫模型(HMM)的基本原理及其在语音识别中的应用。
- 答案:
- 隐马尔可夫模型(HMM)的基本原理: HMM是一种统计模型,用于描述由隐藏的马尔可夫链随机生成的观测序列。HMM包含两个随机过程:
- 隐藏状态序列:表示系统的内部状态,状态之间的转移遵循马尔可夫性质,即当前状态只依赖于前一个状态。
- 观测序列:每个隐藏状态生成一个观测值,观测值依赖于当前状态。
- HMM在语音识别中的应用:
- 信号预处理:对语音信号进行预加重、加窗等处理。
- 特征提取:提取语音信号的特征参数,如MFCC(梅尔频率倒谱系数)。
- 训练HMM:使用训练数据对HMM进行训练,建立语音模板和模型。
- 测试集识别:使用训练好的HMM对测试语音进行识别,通过计算观测序列的概率来确定最可能的语音类别。
- HMM在语音识别中广泛应用,因为它能够很好地处理语音信号的时变性和短时平稳性,并且能够通过统计方法有效地建模语音的动态特性。
- 隐马尔可夫模型(HMM)的基本原理: HMM是一种统计模型,用于描述由隐藏的马尔可夫链随机生成的观测序列。HMM包含两个随机过程: