
socket 套接字
个人学习笔记,参照大丙老师的博客:爱编程的大丙
1. 概念
-
局域网和广域网
- 局域网:局域网将一定区域内的各种计算机、外部设备和数据库连接起来形成计算机通信的私有网络。
- 广域网:又称广域网、外网、公网。是连接不同地区局域网或城域网计算机通信的远程公共网络。
-
IP(Internet Protocol):本质是一个整形数,用于表示计算机在网络中的地址。IP协议版本有两个:IPv4和IPv6
- IPv4(Internet Protocol version4):
- 使用一个32位的整形数描述一个IP地址,4个字节,int型
- 也可以使用一个点分十进制字符串描述这个IP地址:
192.168.247.135 - 分成了4份,每份1字节,8bit(char),最大值为 255
0.0.0.0是最小的IP地址255.255.255.255是最大的IP地址
- 按照IPv4协议计算,可以使用的IP地址共有 2^32 个
- IPv6(Internet Protocol version6):
- 使用一个128位的整形数描述一个IP地址,16个字节
- 也可以使用一个字符串描述这个IP地址:
2001:0db8:3c4d:0015:0000:0000:1a2f:1a2b - 分成了8份,每份2字节,每一部分以16进制的方式表示
- 按照IPv6协议计算,可以使用的IP地址共有 2^128 个
- IPv4(Internet Protocol version4):
-
查看IP地址
|
|
- 端口
端口的作用是定位到主机上的某一个进程,通过这个端口进程就可以接受到对应的网络数据了。
比如: 在电脑上运行了微信和QQ, 小明通过客户端给我的的微信发消息, 电脑上的微信就收到了消息, 为什么?
- 运行在电脑上的微信和QQ都绑定了不同的端口
- 通过IP地址可以定位到某一台主机,通过端口就可以定位到主机上的某一个进程
- 通过指定的IP和端口,发送数据的时候对端就能接受到数据了
端口也是一个整形数 unsigned short ,一个16位整形数,有效端口的取值范围是:0 ~ 65535(0 ~ 2^16-1)
提问:计算机中所有的进程都需要关联一个端口吗,一个端口可以被重复使用吗?
不需要,如果这个进程不需要网络通信,那么这个进程就不需要绑定端口的
一个端口只能给某一个进程使用,多个进程不能同时使用同一个端口
- OSI/ISO 网络分层模型
OSI(Open System Interconnect),即开放式系统互联。 一般都叫OSI参考模型,是ISO(国际标准化组织组织)在1985年研究的网络互联模型。
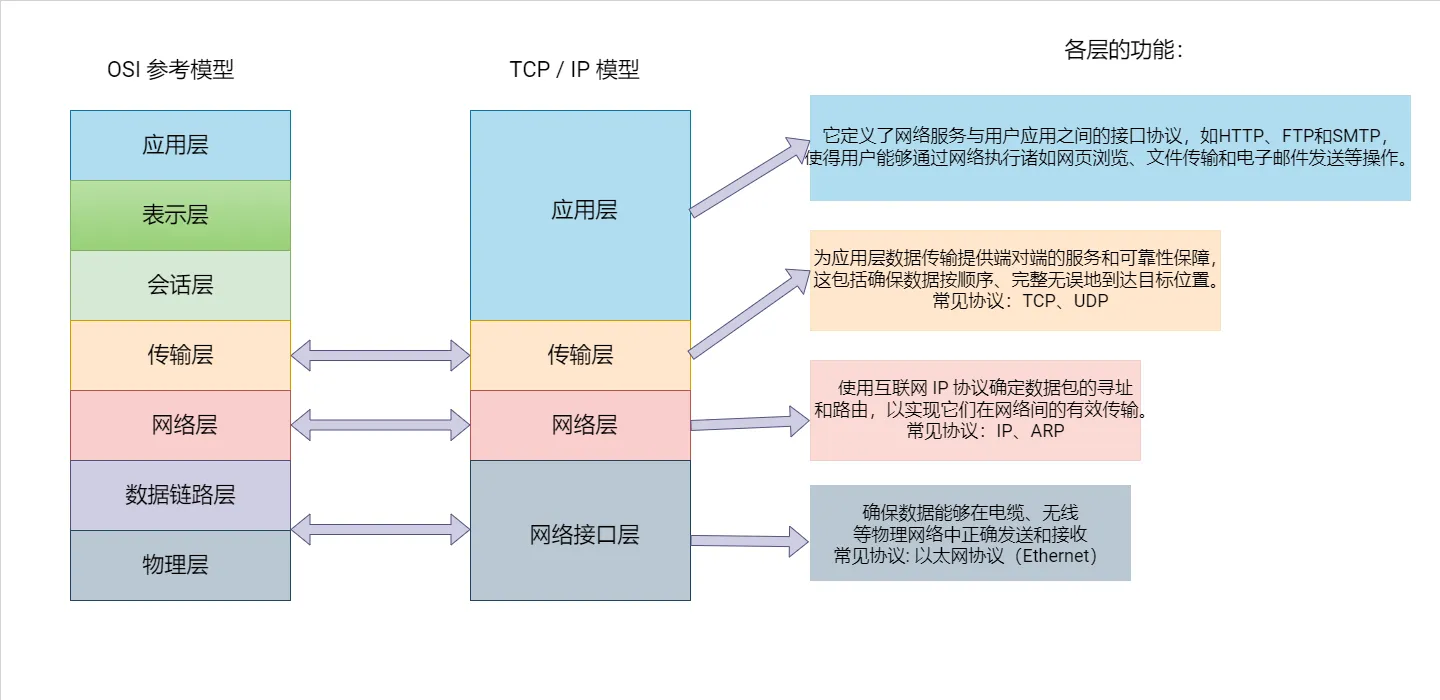
- 物理层:负责最后将信息编码成电流脉冲或其它信号用于网上传输
- 数据链路层:
- 数据链路层通过物理网络链路供数据传输
- 规定了0和1的分包形式,确定了网络数据包的形式
- 网络层:
- 网络层负责在源和终点之间建立连接
- 此处需要确定计算机的位置,通过IPv4,IPv6格式的IP地址来找到对应的主机
- 传输层:
- 传输层向高层提供可靠的端到端的网络数据流服务
- 每一个应用程序都会在网卡注册一个端口号,该层就是端口与端口的通信
- 会话层:
- 会话层建立、管理和终止表示层与实体之间的通信会话
- 建立一个连接(自动的手机信息、自动的网络寻址)
- 表示层:
- 对应用层数据编码和转化
- 确保以一个系统应用层发送的信息可以被另一个系统应用层识别
- 应用层:
- 为应用程序提供网络服务
- 定义了应用程序之间交互的协议和方法
2. 网络协议
网络协议指的是计算机网络中互相通信的对等实体之间交换信息时所必须遵守的规则的集合。一般系统网络协议包括五个部分:通信环境,传输服务,词汇表,信息的编码格式,时序、规则和过程。先来通过下面几幅图了解一下常用的网络协议的格式:
- TCP协议 -> 传输层协议
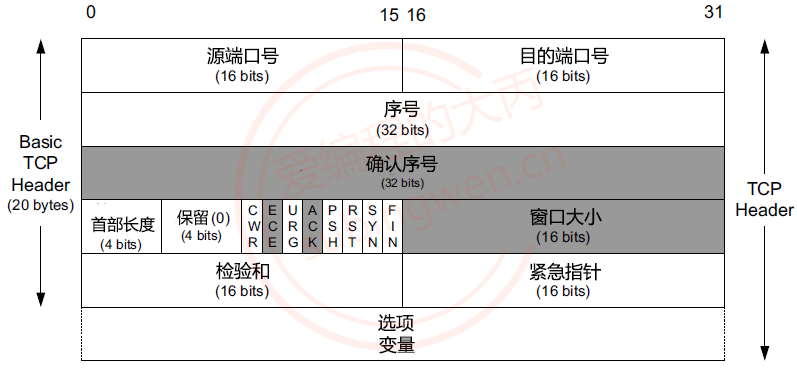
- UDP协议 -> 传输层协议

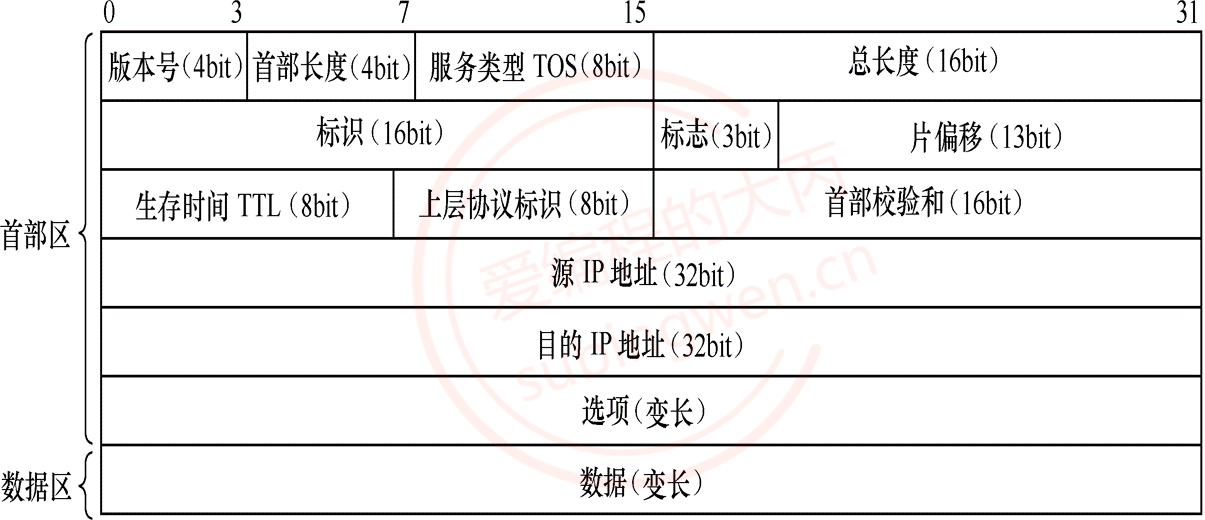
- IP协议 -> 网络层协议
- 以太网帧协议 -> 网络接口层协议
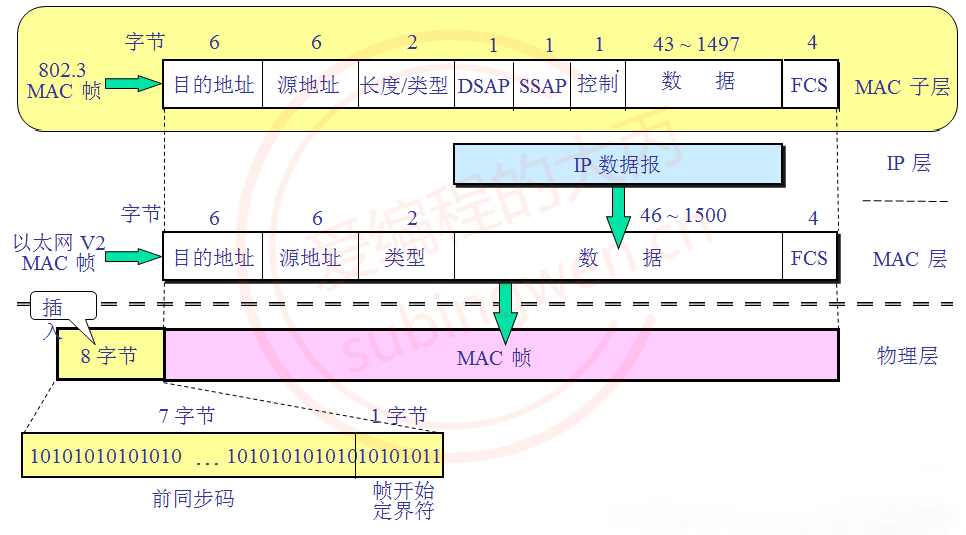
- 数据的封装
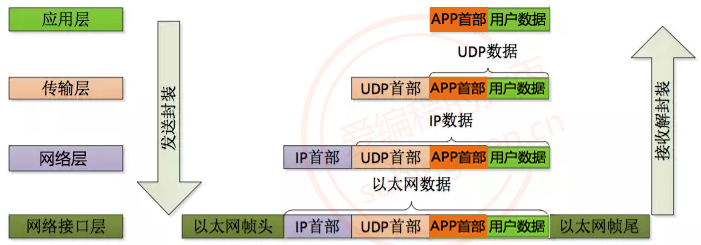
在网络通信的时候, 程序猿需要负责的应用层数据的处理(最上层)
- 应用层的数据可以使用某些协议进行封装, 也可以不封装
- 程序猿需要调用发送数据的接口函数,将数据发送出去
- 程序猿调用的API做底层数据处理
- 传输层使用传输层协议打包数据
- 网络层使用网络层协议打包数据
- 网络接口层使用网络接口层协议打包数据
- 数据被发送到internet
- 接收端接收到发送端的数据
- 程序猿调用接收数据的函数接收数据
- 调用的API做相关的底层处理:
- 网络接口层拆包 ==> 网络层的包
- 网络层拆包 ==> 网络层的包
- 传输层拆包 ==> 传输层数据
- 如果应用层也使用了协议对数据进行了封装,数据的包的解析需要程序猿做
3. socket编程
Socket套接字由远景研究规划局(Advanced Research Projects Agency, ARPA)资助加里福尼亚大学伯克利分校的一个研究组研发。其目的是将TCP/IP协议相关软件移植到UNIX类系统中。设计者开发了一个接口,以便应用程序能简单地调用该接口通信。这个接口不断完善,最终形成了Socket套接字。Linux系统采用了Socket套接字,因此,Socket接口就被广泛使用,到现在已经成为事实上的标准。与套接字相关的函数被包含在头文件sys/socket.h中。
通过上面的描述可以得知,套接字对应程序猿来说就是一套网络通信的接口,使用这套接口就可以完成网络通信。网络通信的主体主要分为两部分:客户端和服务器端。在客户端和服务器通信的时候需要频繁提到三个概念:IP、端口、通信数据,下面介绍一下需要注意的一些细节问题。
3.1 字节序
在各种计算机体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机通信领域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双字等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正确的编/译码从而导致通信失败。
字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序,也就是说对于单字符来说是没有字节序问题的,字符串是单字符的集合,因此字符串也没有字节序问题。
目前在各种体系的计算机中通常采用的字节存储机制主要有两种:Big-Endian 和 Little-Endian,下面先从字节序说起。
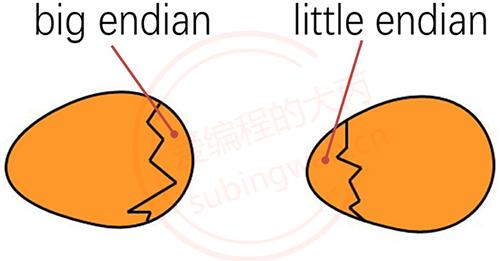
大小端的这个名词最早出现在《格列佛游记》中,里边记载了两个征战的强国,你不会想到的是,他们打仗竟然和剥鸡蛋的顺序有关。很多人认为,剥鸡蛋时应该打破鸡蛋较大的一端,这群人被称作"大端(Big endian)派"。可是那时皇帝儿子小时候吃鸡蛋的时候碰巧将一个手指弄破了。所以,当时的皇帝就下令剥鸡蛋必须打破鸡蛋较小的一端,违令者重罚,由此产生了"小端(Little endian)派"。
老百姓们对这项命令极其反感,由此引发了6次叛乱,其中一个皇帝送了命,另一个丢了王位。据估计,先后几次有11000人情愿受死也不肯去打破鸡蛋较小的一端!
-
Little-Endian -> 主机字节序 (小端)
- 数据的
低位字节存储到内存的低地址位, 数据的高位字节存储到内存的高地址位 - 我们使用的PC机,数据的存储默认使用的是小端
- 数据的
-
Big-Endian -> 网络字节序 (大端)
- 据的
低位字节存储到内存的高地址位, 数据的高位字节存储到内存的低地址位 套接字通信过程中操作的数据都是大端存储的,包括:接收/发送的数据、IP地址、端口。
- 据的
-
字节序举例
|
|
- 函数
BSD Socket提供了封装好的转换接口,方便程序员使用。包括从主机字节序到网络字节序的转换函数:htons、htonl;从网络字节序到主机字节序的转换函数:ntohs、ntohl。
|
|
3.2 IP地址转换
虽然IP地址本质是一个整形数,但是在使用的过程中都是通过一个字符串来描述,下面的函数描述了如何将一个字符串类型的IP地址进行大小端转换:
|
|
- 参数:
- af: 地址族(IP地址的家族包括ipv4和ipv6)协议
- AF_INET: ipv4格式的ip地址
- AF_INET6: ipv6格式的ip地址
- src: 传入参数, 对应要转换的点分十进制的ip地址: 192.168.1.100
- dst: 传出参数, 函数调用完成, 转换得到的大端整形IP被写入到这块内存中
- af: 地址族(IP地址的家族包括ipv4和ipv6)协议
- 返回值:成功返回1,失败返回0或者-1
|
|
- 参数:
- af: 地址族协议
- AF_INET: ipv4格式的ip地址
- AF_INET6: ipv6格式的ip地址
- src: 传入参数, 这个指针指向的内存中存储了大端的整形IP地址
- dst: 传出参数, 存储转换得到的小端的点分十进制的IP地址
- size: 修饰dst参数的, 标记dst指向的内存中最多可以存储多少个字节
- af: 地址族协议
- 返回值:
- 成功: 指针指向第三个参数对应的内存地址, 通过返回值也可以直接取出转换得到的IP字符串
- 失败: NULL
还有一组函数也能进程IP地址大小端的转换,但是只能处理ipv4的ip地址:
|
|
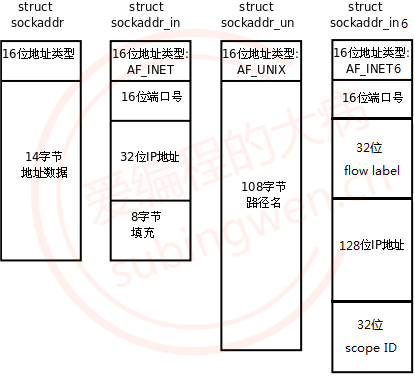
3.3 sockaddr 数据结构
|
|
3.4 套接字函数
使用套接字通信函数需要包含头文件<arpa/inet.h>,包含了这个头文件<sys/socket.h>就不用在包含了。
|
|
- 参数:
- domain: 使用的地址族协议
- AF_INET: 使用IPv4格式的ip地址
- AF_INET6: 使用IPv6格式的ip地址
- type:
- SOCK_STREAM: 使用流式的传输协议
- SOCK_DGRAM: 使用报式(报文)的传输协议
- protocol: 一般写0即可, 使用默认的协议
- SOCK_STREAM: 流式传输默认使用的是tcp
- SOCK_DGRAM: 报式传输默认使用的udp
- domain: 使用的地址族协议
- 返回值:
- 成功: 可用于套接字通信的文件描述符
- 失败: -1
函数的返回值是一个文件描述符,通过这个文件描述符可以操作内核中的某一块内存,网络通信是基于这个文件描述符来完成的。
|
|
- 参数:
- sockfd: 监听的文件描述符, 通过socket()调用得到的返回值
- addr: 传入参数, 要绑定的IP和端口信息需要初始化到这个结构体中,
IP和端口要转换为网络字节序 - addrlen: 参数addr指向的内存大小, sizeof(struct sockaddr)
- 返回值:成功返回0,失败返回-1
|
|
- 参数:
- sockfd: 文件描述符, 可以通过调用socket()得到,在监听之前必须要绑定 bind()
- backlog: 同时能处理的最大连接要求,最大值为128
- 返回值:函数调用成功返回0,调用失败返回 -1
|
|
- 参数:
- sockfd: 监听的文件描述符
- addr: 传出参数, 里边存储了建立连接的客户端的地址信息
- addrlen: 传入传出参数,用于存储addr指向的内存大小
- 返回值:函数调用成功,得到一个文件描述符, 用于和建立连接的这个客户端通信,调用失败返回 -1
这个函数是一个阻塞函数,当没有新的客户端连接请求的时候,该函数阻塞;当检测到有新的客户端连接请求时,阻塞解除,新连接就建立了,得到的返回值也是一个文件描述符,基于这个文件描述符就可以和客户端通信了。
|
|
- 参数:
- sockfd: 用于通信的文件描述符, accept() 函数的返回值
- buf: 指向一块有效内存, 用于存储接收是数据
- size: 参数buf指向的内存的容量
- flags: 特殊的属性, 一般不使用, 指定为 0
- 返回值:
- 大于0:实际接收的字节数
- 等于0:对方断开了连接
- -1:接收数据失败了
如果连接没有断开,接收端接收不到数据,接收数据的函数会阻塞等待数据到达,数据到达后函数解除阻塞,开始接收数据,当发送端断开连接,接收端无法接收到任何数据,但是这时候就不会阻塞了,函数直接返回0。
|
|
- 参数:
- fd: 通信的文件描述符, accept() 函数的返回值
- buf: 传入参数, 要发送的字符串
- len: 要发送的字符串的长度
- flags: 特殊的属性, 一般不使用, 指定为 0
- 返回值:
- 大于0:实际发送的字节数,和参数len是相等的
- -1:发送数据失败了
|
|
- 参数:
- sockfd: 通信的文件描述符, 通过调用socket()函数就得到了
- addr: 存储了要连接的服务器端的地址信息: iP 和 端口,这个IP和端口也需要转换为大端然后再赋值
- addrlen: addr指针指向的内存的大小 sizeof(struct sockaddr)
- 返回值:连接成功返回0,连接失败返回-1
4. TCP通信流程
TCP是一个面向连接的,安全的,流式传输协议,这个协议是一个传输层协议。
- 面向连接:是一个双向连接,通过三次握手完成,断开连接需要通过四次挥手完成。
- 安全:tcp通信过程中,会对发送的每一数据包都会进行校验, 如果发现数据丢失, 会自动重传
- 流式传输:发送端和接收端处理数据的速度,数据的量都可以不一致
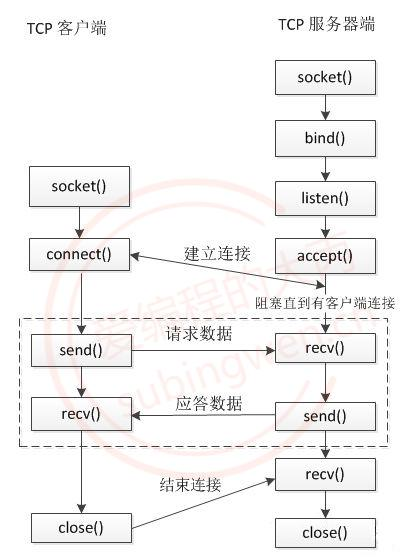
4.1 服务器端通信流程
- 创建用于监听的套接字, 这个套接字是一个文件描述符
|
|
- 将得到的监听的文件描述符和本地的IP 端口进行绑定
|
|
- 设置监听(成功之后开始监听, 监听的是客户端的连接)
|
|
- 等待并接受客户端的连接请求, 建立新的连接, 会得到一个新的文件描述符(通信的)
没有新连接请求就阻塞
|
|
- 通信,读写操作默认都是阻塞的
|
|
- 断开连接, 关闭套接字
|
|
在tcp的服务器端, 有两类文件描述符:
- 监听的文件描述符
- 只需要有一个
- 不负责和客户端通信, 负责检测客户端的连接请求, 检测到之后调用accept就可以建立新的连接
- 通信的文件描述符
- 负责和建立连接的客户端通信
- 如果有N个客户端和服务器建立了新的连接, 通信的文件描述符就有N个,每个客户端和服务器都对应一个通信的文件描述符
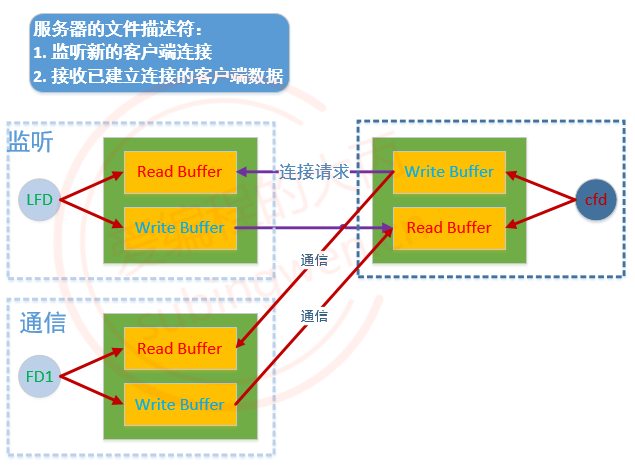
文件描述符对应的内存结构:
- 一个文件文件描述符对应两块内存, 一块内存是读缓冲区, 一块内存是写缓冲区
- 读数据: 通过文件描述符将内存中的数据读出, 这块内存称之为读缓冲区
- 写数据: 通过文件描述符将数据写入到某块内存中, 这块内存称之为写缓冲区
监听的文件描述符:
- 客户端的连接请求会发送到服务器端监听的文件描述符的读缓冲区中
- 读缓冲区中有数据, 说明有新的客户端连接
- 调用accept()函数, 这个函数会检测监听文件描述符的读缓冲区
- 检测不到数据, 该函数阻塞
- 如果检测到数据, 解除阻塞, 新的连接建立
通信的文件描述符:
- 客户端和服务器端都有通信的文件描述符
- 发送数据:调用函数 write() / send(),数据进入到内核中
- 数据并没有被发送出去, 而是将数据写入到了通信的文件描述符对应的写缓冲区中
- 内核检测到通信的文件描述符写缓冲区中有数据, 内核会将数据发送到网络中
- 接收数据: 调用的函数 read() / recv(), 从内核读数据
- 数据如何进入到内核程序猿不需要处理, 数据进入到通信的文件描述符的读缓冲区中
- 数据进入到内核, 必须使用通信的文件描述符, 将数据从读缓冲区中读出即可
4.2 客户端的通信流程
在单线程的情况下客户端通信的文件描述符有一个, 没有监听的文件描述符
- 创建一个通信的套接字
|
|
- 连接服务器, 需要知道服务器绑定的IP和端口
|
|
- 通信
|
|
- 断开连接, 关闭文件描述符(套接字)
|
|